Harvesting services¶
Introduction¶
This chapter provides a detailed explanation of the GeoNetwork’s harvesting services. These services allow a complete control over the harvesting behaviour. They are used by the web interface and can be used by any other client.
xml.harvesting.get¶
Retrieves information about one or all configured harvesting nodes.
Request¶
Called with no parameters returns all nodes. Example:
<request/>
Otherwise, an id parameter can be specified:
<request>
<id>123</id>
</request>
Response¶
When called with no parameters the service provide its output inside a nodes container. You get as many node elements as are configured.
Example of an xml.harvesting.get response for a GeoNetwork node:
<nodes>
<node id="125" type="geonetwork">
<site>
<name>test 1</name>
<UUID>0619cc50-708b-11da-8202-000d9335aaae</uuid>
<host>localhost</host>
<port>8080</port>
<servlet>geonetwork</servlet>
<account>
<use>false</use>
<username />
<password />
</account>
</site>
<searches>
<search>
<freeText />
<title />
<abstract />
<keywords />
<digital>false</digital>
<hardcopy>false</hardcopy>
<source>
<UUID>0619cc50-708b-11da-8202-000d9335906e</uuid>
<name>Food and Agriculture organisation</name>
</source>
</search>
</searches>
<options>
<every>90</every>
<oneRunOnly>false</oneRunOnly>
<status>inactive</status>
</options>
<info>
<lastRun />
<running>false</running>
</info>
<groupsCopyPolicy>
<group name="all" policy="copy"/>
<group name="mygroup" policy="createAndCopy"/>
</groupsCopyPolicy>
<categories>
<category id="4"/>
</categories>
</node>
</nodes>
If you specify an id, you get a response like the one below.
Example of an xml.harvesting.get response for a WebDAV node:
<node id="165" type="webdav">
<site>
<name>test 1</name>
<UUID>0619cc50-708b-11da-8202-000d9335aaae</uuid>
<url>http://www.mynode.org/metadata</url>
<icon>default.gif</icon>
<account>
<use>true</use>
<username>admin</username>
<password>admin</password>
</account>
</site>
<options>
<every>90</every>
<oneRunOnly>false</oneRunOnly>
<recurse>false</recurse>
<validate>true</validate>
<status>inactive</status>
</options>
<privileges>
<group id="0">
<operation name="view" />
</group>
<group id="14">
<operation name="download" />
</group>
</privileges>
<categories>
<category id="2"/>
</categories>
<info>
<lastRun />
<running>false</running>
</info>
</node>
The node’s structure has a common XML format, plus some additional information provided by the harvesting types. In the following structure, each element has a cardinality specified using the [x..y] notation, where x and y denote the minimum and the maximum values. The cardinality [1..1] is omitted for clarity.
- node: The root element. It has a mandatory id attribute that
represents the internal identifier and a mandatory type attribute
which indicates the harvesting type.
- site: A container for site information.
- name (string): The node’s name used to describe the harvesting.
- UUID (string): This is a system generated unique identifier associated to the harvesting node. This is used as the source field into the Metadata table to group all metadata from the remote node.
- account: A container for account information.
- use (boolean): true means that the harvester will use the provided username and password to authenticate itself. The authentication mechanism depends on the harvesting type.
- username (string): Username on the remote node.
- password (string): Password on the remote node.
- options: A container for generic options.
- every (integer): Harvesting interval in minutes.
- oneRunOnly (boolean): After the first run, the entry’s status will be set to inactive.
- status (string): Indicates if the harvesting from this node is stopped (inactive) or if the harvester is waiting for the timeout (active).
- privileges [0..1]: A container for privileges that must be
associated to the harvested metadata. This optional element
is present only if the harvesting type supports it.
- group [0..n]: A container for allowed operations
associated to this group. It has the id attribute
which value is the identifier of a GeoNetwork group.
- operation [0..n]: Specifies an operation to associate to the containing group. It has a name attribute which value is one of the supported operation names. The only supported operations are: view, dynamic, featured.
- group [0..n]: A container for allowed operations
associated to this group. It has the id attribute
which value is the identifier of a GeoNetwork group.
- categories [0..1]: This is a container for categories to
assign to each imported metadata. This optional element is
present if the harvesting type supports it.
- category (integer) [0..n]: Represents a local category and the id attribute is its local identifier.
- info: A container for general information.
- lastRun (string): The lastRun element will be filled as soon as the harvester starts harvesting from this entry. The value is the
- running (boolean): True if the harvester is currently running.
- error: This element will be present if the harvester
encounters an error during harvesting.
- code (string): The error code, in string form.
- message (string): The description of the error.
- object (string): The object that caused the error (if any). This element can be present or not depending on the case.
- site: A container for site information.
Errors¶
- ObjectNotFoundEx If the id parameter is provided but the node cannot be found.
xml.harvesting.add¶
Create a new harvesting node. The node can be of any type supported by GeoNetwork (GeoNetwork node, web folder etc...). When a new node is created, its status is set to inactive. A call to the xml.harvesting.start service is required to start harvesting.
Request¶
The service requires an XML tree with all information the client wants to add. In the following sections, default values are given in parenthesis (after the parameter’s type) and are used when the parameter is omitted. If no default is provided, the parameter is mandatory. If the type is boolean, only the true and false strings are allowed.
All harvesting nodes share a common XML structure that must be honoured. Please, refer to the previous section for elements explanation. Each node type can add extra information to that structure. The common structure is here described:
- node: The root container. The type attribute is mandatory and
must be one of the supported harvesting types.
- site [0..1]
- name (string, ”)
- account [0..1]
- use (boolean, ’false’)
- username (string, ”)
- password (string, ”)
- options [0..1]
- every (integer, ’90’)
- oneRunOnly (boolean, ’false’)
- privileges [0..1]: Can be omitted but doing so the
harvested metadata will not be visible. Please note that
privileges are taken into account only if the harvesting
type supports them.
- group [0..n]: It must have the id attribute which
value should be the identifier of a GeoNetwork
group. If the id is not a valid group id, all
contained operations will be discarded.
- operation [0..n]: It must have a name attribute which value must be one of the supported operation names.
- group [0..n]: It must have the id attribute which
value should be the identifier of a GeoNetwork
group. If the id is not a valid group id, all
contained operations will be discarded.
- categories [0..1]: Please, note that categories will be
assigned to metadata only if the harvesting type supports
them.
- category (integer) [0..n]: The mandatory id attribute is the category’s local identifier.
- site [0..1]
Please note that even if clients can store empty values (”) for many parameters, before starting the harvesting entry those parameters should be properly set in order to avoid errors.
In the following sections, the XML structures described inherit from this one here so the common elements have been removed for clarity reasons (unless they are containers and contain new children).
Standard GeoNetwork harvesting¶
To create a node capable of harvesting from another GeoNetwork node, the following XML information should be provided:
- node: The type attribute is mandatory and must be GeoNetwork.
- site
- host (string, ”): The GeoNetwork node’s host name or IP address.
- port (string, ’80’): The port to connect to.
- servlet (string, ’geonetwork’): The servlet name chosen in the remote site.
- searches [0..1]: A container for search parameters.
- search [0..n]: A container for a single search on
a siteID. You can specify 0 or more searches. If no
search element is provided, an unconstrained search
is performed.
- freeText (string, ”) : Free text to search. This and the following parameters are the same used during normal search using the web interface.
- title (string, ”): Search the title field.
- abstract (string, ”) : Search the abstract field.
- keywords (string, ”) : Search the keywords fields.
- digital (boolean, ’false’): Search for metadata in digital form.
- hardcopy (boolean, ’false’): Search for metadata in printed form.
- source (string, ”): One of the sources present on the remote node.
- search [0..n]: A container for a single search on
a siteID. You can specify 0 or more searches. If no
search element is provided, an unconstrained search
is performed.
- groupsCopyPolicy [0..1]: Container for copy policies of
remote groups. This mechanism is used to retain remote
metadata privileges.
- group: There is one copy policy for each remote group. This element must have 2 mandatory attributes: name and policy. The name attribute is the remote group’s name. If the remote group is renamed, it is not found anymore and the copy policy is skipped. The policy attribute represents the policy itself and can be: copy, createAndCopy, copyToIntranet. copy means that remote privileges are copied locally if there is locally a group with the same name as the name attribute. createAndCopy works like copy but the group is created locally if it does not exist. copyToIntranet works only for the remote group named all, which represents the public group. This policy copies privileges of the remote group named all to the local Intranet group. This is useful to restrict metadata access.
- site
Example of an xml.harvesting.add request for a GeoNetwork node:
<node type="geonetwork">
<site>
<name>South Africa</name>
<host>south.africa.org</host>
<port>8080</port>
<servlet>geonetwork</servlet>
<account>
<use>true</use>
<username>admin</username>
<password>admin</password>
</account>
</site>
<searches>
<search>
<freeText />
<title />
<abstract />
<keywords />
<digital>true</digital>
<hardcopy>false</hardcopy>
<source>0619cc50-708b-11da-8202-000d9335906e</source>
</search>
</searches>
<options>
<every>90</every>
<oneRunOnly>false</oneRunOnly>
</options>
<groupsCopyPolicy>
<group name="all" policy="copy"/>
<group name="mygroup" policy="createAndCopy"/>
</groupsCopyPolicy>
<categories>
<category id="4"/>
</categories>
</node>
WebDAV harvesting¶
To create a web DAV node, the following XML information should be provided.
- node: The type attribute is mandatory and must be WebDAV.
- site
- url (string, ”): The URL to harvest from. If provided, must be a valid URL starting with HTTP://.
- icon (string, ’default.gif’): Icon file used to represent this node in the search results. The icon must be present into the images/harvesting folder.
- options
- recurse (boolean, ’false’): When true, folders are scanned recursively to find metadata.
- validate (boolean, ’false’): When true, GeoNetwork will validate every metadata against its schema. If the metadata is not valid, it will not be imported.
- site
This type supports both privileges and categories assignment.
Example of an xml.harvesting.add request for a WebDAV node:
<node type="webdav">
<site>
<name>Asia remote node</name>
<url>http://www.mynode.org/metadata</url>
<icon>default.gif</icon>
<account>
<use>true</use>
<username>admin</username>
<password>admin</password>
</account>
</site>
<options>
<every>90</every>
<oneRunOnly>false</oneRunOnly>
<recurse>false</recurse>
<validate>true</validate>
</options>
<privileges>
<group id="0">
<operation name="view" />
</group>
<group id="14">
<operation name="features" />
</group>
</privileges>
<categories>
<category id="4"/>
</categories>
</node>
CSW harvesting¶
To create a node to harvest from a CSW capable server, the following XML information should be provided:
- node: The type attribute is mandatory and must be csw.
- site
- capabilitiesUrl (string): URL of the capabilities file that will be used to retrieve the operations address.
- icon (string, ’default.gif’) : Icon file used to represent this node in the search results. The icon must be present into the images/harvesting folder.
- searches [0..1]
- search [0..n]: Contains search parameters. If
this element is missing, an unconstrained search
will be performed.
- freeText (string, ”) : Search the entire metadata.
- title (string, ”): Search the dc:title queryable.
- abstract (string, ”): Search the dc:abstract queryable.
- subject (string, ”): Search the dc:subject queryable.
- search [0..n]: Contains search parameters. If
this element is missing, an unconstrained search
will be performed.
- site
This type supports both privileges and categories assignment.
xml_request_harvesting_add_csw shows an example of an XML request to create a CSW entry.
Example of an xml.harvesting.add request for a CSW node:
<node type="csw">
<site>
<name>Minos CSW server</name>
<capabilitiesUrl>http://www.minos.org/csw?request=GetCapabilities
&amp;service=CSW&amp;acceptVersions=2.0.1</capabilitiesUrl>
<icon>default.gif</icon>
<account>
<use>true</use>
<username>admin</username>
<password>admin</password>
</account>
</site>
<options>
<every>90</every>
<oneRunOnly>false</oneRunOnly>
<recurse>false</recurse>
<validate>true</validate>
</options>
<privileges>
<group id="0">
<operation name="view" />
</group>
<group id="14">
<operation name="features" />
</group>
</privileges>
<categories>
<category id="4"/>
</categories>
</node>
Response¶
The service’s response is the output of the xml.harvesting.get service of the newly created node.
xml.harvesting.update¶
This service is responsible for changing the node’s parameters. A typical request has a node root element and must include the id attribute:
<node id="24">
...
</node>
The body of the node element depends on the node’s type. The update policy is this:
- If an element is specified, the associated parameter is updated.
- If an element is not specified, the associated parameter will not be changed.
So, you need to specify only the elements you want to change. However, there are some exceptions:
- privileges: If this element is omitted, privileges will not be changed. If specified, new privileges will replace the old ones.
- categories: Like the previous one.
- searches: Some harvesting types support multiple searches on the same remote note. When supported, the updated behaviour should be like the previous ones.
Note that you cannot change the type of an node once it has been created.
Request¶
The request is the same as that used to add an entry. Only the id attribute is mandatory.
Response¶
The response is the same as the xml.harvesting.get called on the updated entry.
xml.harvesting.remove /start /stop /run¶
These services are put together because they share a common request interface. Their purpose is obviously to remove, start, stop or run a harvesting node. In detail:
- remove: Remove a node. Completely deletes the harvesting instance.
- start: When created, a node is in the inactive state. This operation makes it active, that is the countdown is started and the harvesting will be performed at the timeout.
- stop: Makes a node inactive. Inactive nodes are never harvested.
- run: Just start the harvester now. Used to test the harvesting.
Request¶
A set of ids to operate on. Example:
<request>
<id>123</id>
<id>456</id>
<id>789</id>
</request>
If the request is empty, nothing is done.
Response¶
The same as the request but every id has a status attribute indicating the success or failure of the operation. For example, the response to the previous request could be:
<request>
<id status="ok">123</id>
<id status="not-found">456</id>
<id status="inactive">789</id>
</request>
Summary of status values summarises, for each service, the possible status values.
Summary of status values¶
| Status value | remove | start | stop | run |
|---|---|---|---|---|
| ok | 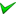 |
|
|
|
| not-found | |
|
|
|
| inactive | |
|||
| already-inactive | |
|||
| already-active | |
|||
| already-running | |


